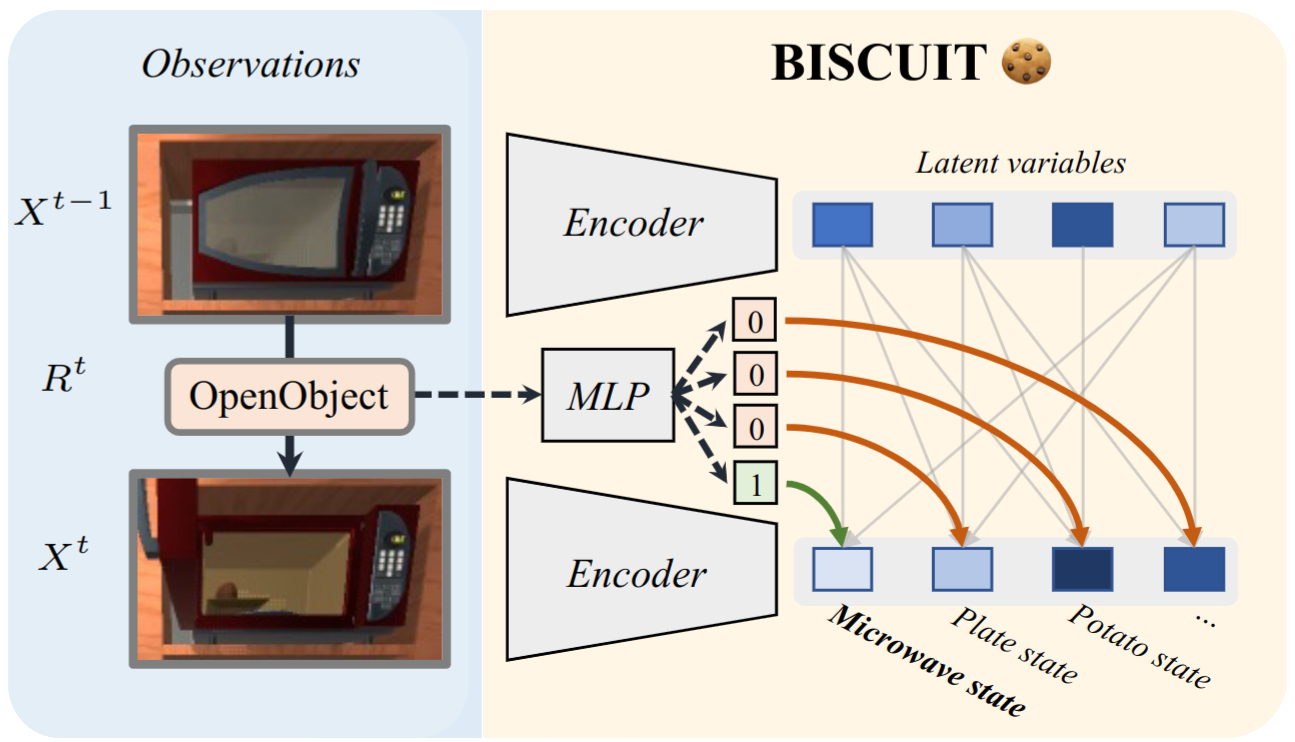
BISCUIT learns causal variables from interactivate environments with low-level action information.
Abstract
Identifying the causal variables of an environment and how to intervene on them is of core value in applications such as robotics and embodied AI.
While an agent can commonly interact with the environment and may implicitly perturb the behavior of some of these causal variables, often the targets it affects remain unknown.
In this paper, we show that causal variables can still be identified for many common setups, e.g., additive Gaussian noise models, if the agent's interactions with a causal variable can be described by an unknown binary variable.
This happens when each causal variable has two different mechanisms, e.g., an observational and an interventional one.
Using this identifiability result, we propose BISCUIT, a method for simultaneously learning causal variables and their corresponding binary interaction variables.
On three robotic-inspired datasets, BISCUIT accurately identifies causal variables and can even be scaled to complex, realistic environments for embodied AI.
What is BISCUIT?
BISCUIT is a method for learning causal representations from videos of interactive systems.
We refer to a representation as causal if it identifies the causal variables of the environment by disentangling them in a learned, latent space, and models the interactions between the causal variables.
Causal representations are useful for many applications, e.g., for robotics, where we need to reason about the effects of our actions on the environment, as well as interactions between causal variables.
Yet, learning a causal representation is challenging since simply optimizing for maximum likelihood leads to many equally good representations that do not disentangle the causal variables.
Example: A common example of an interactive system is an embodied agent interacting with objects in an environment.
In the kitchen environment of iTHOR, the causal variables are the states of the objects in the kitchen, e.g., the microwave, the stove, the toaster, etc.
The agent can interact with these by, for example, turning on the microwave or opening the cabinet.
When attempting to solve a task like cooking an egg, the agent needs to causally reason about its interactions and effects on causal variables, e.g., the egg needs to be broken in a pan on a burning stove, which inherently requires a causal representation.
Similarly, in CausalWorld, we have a tri-finger robot interacting with objects on the stage, e.g., the cube.
iTHOR: An embodied agent interacting with objects in a kitchen environment.
CausalWorld: A tri-finger robot interacting with objects in a stage.
To discover the causal variables in such environments, BISCUIT uses a novel, practical identifiability result that we prove in the paper.
It is based on the idea that the causal variables of an environment can be identified if the agent's interactions with a causal variable can be described by an unknown binary interaction variable.
Many interactions can be described with a simple binary interaction, for example, when each causal variable has two different mechanisms, e.g., an observational and an interventional one.
Commonly, this binary interaction variable is not known beforehand and, instead, BISCUIT unsupervisedly learns them from low-level action information such as the agent's state or position of its robotic arm.
Example: In our kitchen environment, the agent can interact with objects like the microwave.
If the agent decides to leave the microwave untouched for a time frame, the microwave follows its observational mechanism, e.g., maintains its current state or reducing its timer.
Alternatively, the agent can interact with the microwave by changing its state, e.g., turning it on or off, which corresponds to intervening on the microwave's state.
In this case, the agent's interaction with the microwave can be described by a binary variable, which is 1 if the agent is intervening on the microwave and 0 otherwise.
Similarly, an agent can interact with the plate by picking it up or leaving it untouched, which can also be described by a binary variable.
The value of the causal variable itself does not need to be binary, as the plate position is a 3D continuous variable.
How does BISCUIT work?
BISCUIT uses an encoder-decoder setup to map the video frames to a latent space.
In this latent space, we aim to encode each causal variable in a separate set of dimensions.
This is implemented by modeling a temporal VAE, where the prior of the latent space is conditioned on the previous frame.
Further, we unsupervisedly learn the binary interaction variables via an MLP per latent variable, which takes as input the action information and potentially the previous frame.
By regularizing the MLP output to be binary, BISCUIT learns to encode the causal variables in a disentangled manner.
BISCUIT identifies causal variables from images by learning to encode low-level action information to binary interaction variables.
For visually complex datasets like iTHOR or CausalWorld, the VAE can be replaced with a two-stage training approach.
First, we train a standard autoencoder to reduce the frames to a much lower dimensional latent vector.
Then, we train a normalizing flow on top of the latent space of the autoencoder to map the potentially entangled representation to a causal representation, using the same prior setup as for the VAE.
With this, BISCUIT can accurately identify causal variables and their interactions even on datasets with high-resolution videos.
For more details, check out our paper!
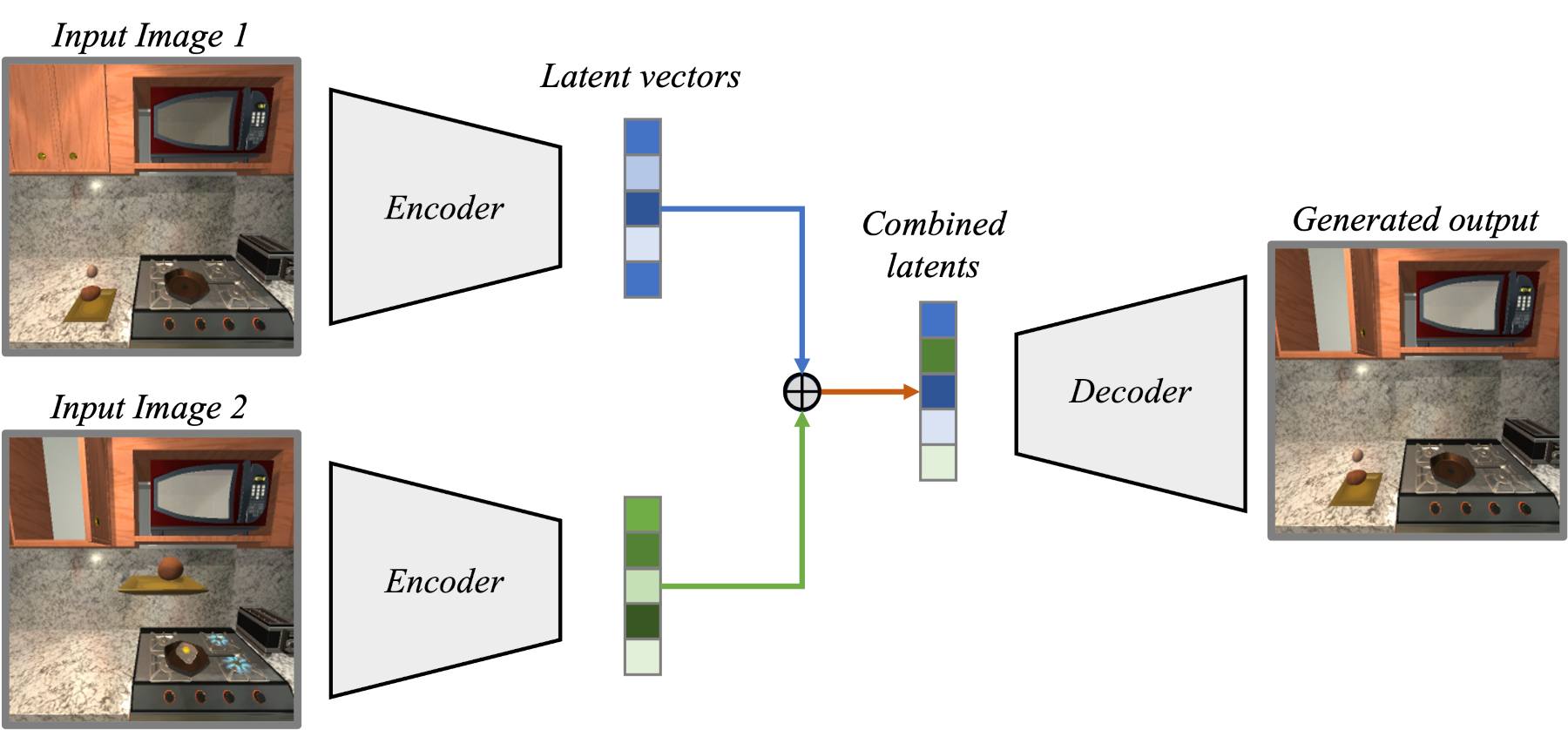
Simulating Interventions in Latent Space
Once the causal representation is learned, we can use it to simulate interventions and generate novel combinations of causal variables.
For example, given a frame, we could ask the question: "How would the same scene look like if we had opened the microwave?".
To do this, we first encode the frame to the latent space and then manipulate the latent variables, in which BISCUIT represents the state of the microwave, to simulate the intervention.
This manipulation is done by encoding a frame to latent space where the microwave is open, and replacing the corresponding latent variables of the original frame with the ones of the open microwave frame.
Finally, we decode the latent representation to generate the new frame, as shown below.
BISCUIT can generate novel combinations of causal variables by combining the latents of two input images.
This process can be done for various combinations of causal variables, e.g., to simulate the effect of turning on the stove and activating the microwave.
In this way, BISCUIT can even generate novel combinations of causal variables that it has never seen during training, such as setting an egg to be uncooked although it is in the pan and the stove is burning.
We show a few example below, and you can generate your own combinations in our demo (coming soon)!
Manipulating Image 1 by turning on the Microwave and the front-left Stove. Note the egg staying uncooked despite the stove being turned on, which the model has never seen in training and shows BISCUIT's ability to perform novel interventions.
Manipulating Image 1 by turning on the front-left Stove.
Manipulating Image 1 by turning on the Microwave and opening the Cabinet.
Manipulating Image 1 by opening the Microwave.
Manipulating Image 1 by turning on the Toaster.
Identifying the Ability to Intervene
Besides the ability to simulate interventions, the learned interaction variables allow BISCUIT to also identify how the agent can intervene on a causal variable.
For example, given a frame, we could ask the question: "What actions can the agent perform to turn on the microwave?".
To do this, we first encode the frame to the latent space, and then feed all possible actions to the MLPs of the latent variables, which predict the binary interaction variable for each action.
All actions, for which the MLP predicts a 1 for the latent variable of the microwave, are the actions that the agent can perform to intervene on the microwave state.
In this way, BISCUIT can identify the affordances of the agent to intervene on individual causal variables of the environment.
In our iTHOR dataset, the actions consist of randomly sampled pixel positions of the objects the agent interacts with, i.e., simulating an agent's mouse click in iTHOR's demo.
Hence, by predicting the binary interaction variable for each pixel position, BISCUIT unsupervisedly segments the objects in the environment and identifies the actions of the agent to interact with them.
We show some examples below, where each color represents the interaction map of a different object in the environment.
Check out our demo (coming soon) to generate interaction maps for new images!
Predicted interaction map of the iTHOR kitchen environment. BISCUIT identifies the interactions between the agent and the objects in the environment acurately.
BISCUIT adapts its interaction variables to the state of the environment. Here, since the Microwave is open, it cannot be turned on and its door is at a different position.
The most challenging task is to disentangle the multiple moving objects, which occasionally can overlap in their predicted interactions.
For picked-up objects, BISCUIT correctly predicts their interaction target on the object itself.
@inproceedings{lippe2023biscuit,
title = {BISCUIT: Causal Representation Learning from Binary Interactions},
author = {Lippe, Phillip and Magliacane, Sara and L{\"o}we, Sindy and Asano, Yuki M and Cohen, Taco and Gavves, Efstratios},
year = 2023,
booktitle = {The 39th Conference on Uncertainty in Artificial Intelligence},
url = {https://openreview.net/forum?id=VS7Dn31xuB}
}