Training Models at Scale Tutorials
We have released 10 new notebooks, implementing parallelism from scratch in JAX/Flax.
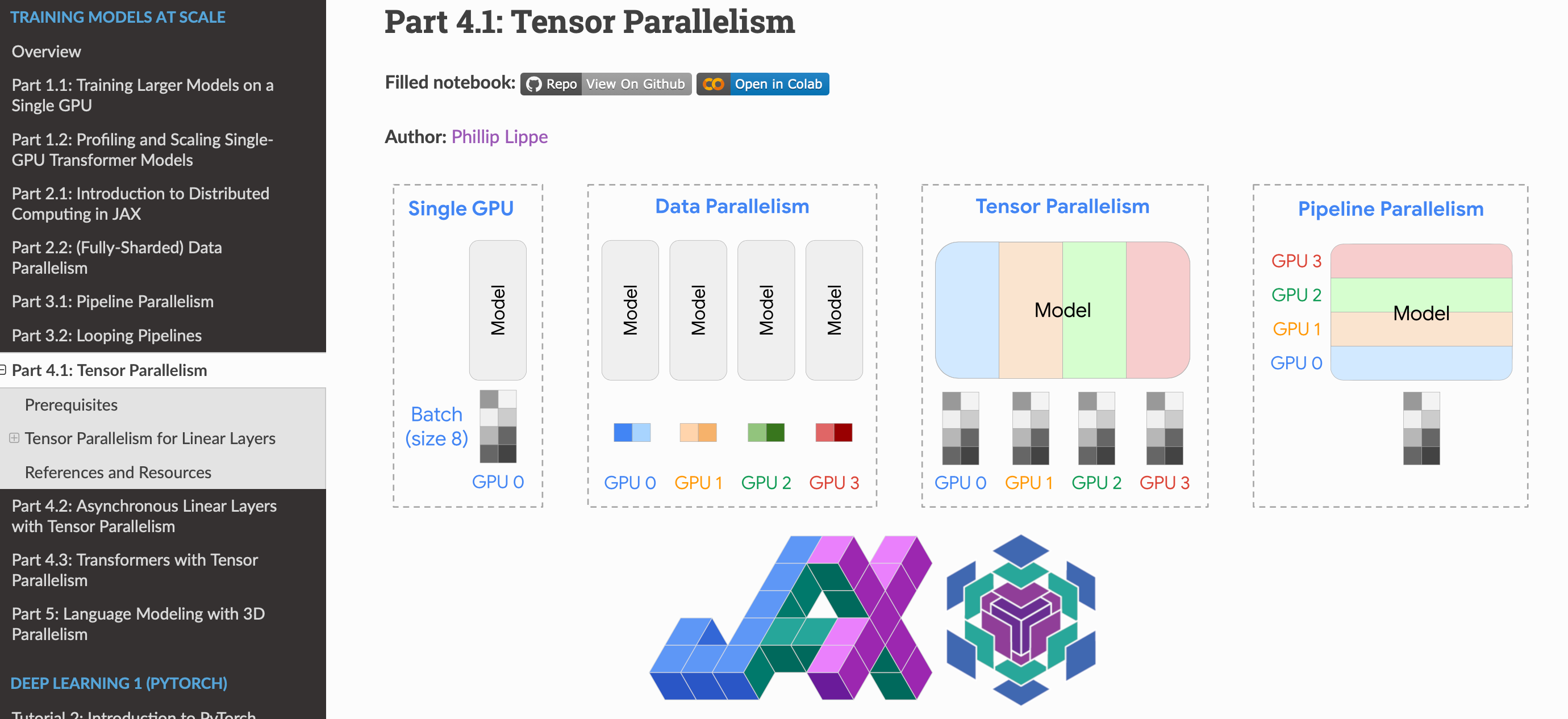
In our newly research UvA DL tutorial series on “Training Models at Scale”, we explore parallelism strategies for training large deep learning models with a parameter count of several billions! The goal of this tutorial is to provide a comprehensive overview of techniques and strategies used for scaling deep learning models, and to provide a hands-on guide to implement these strategies from scratch in JAX with Flax using shard_map.
The field of deep learning has seen a rapid increase in model size over the past years, especially with models like GPT-4, Gemini, Llama, Mistral, and Claude. This trend is driven by the observation that larger models often lead to better performance, and the availability of more powerful hardware. Training large models is challenging, and requires careful consideration of the parallelism strategies to efficiently utilize the available hardware. Hence, understanding and implementing parallelism strategies is crucial for training large models. This is the focus of this tutorial series.
Do you want to train massive deep learning models with ease? Our 10 new tutorial notebooks of our popular UvA DL course show you how, implementing data, pipeline and tensor parallelism (and more) from scratch in JAX+Flax! 🚀🚀
— Phillip Lippe (@phillip_lippe) March 7, 2024
Check them out here: https://t.co/7AtaB7j8l9
🧵 1/11 pic.twitter.com/iYCNUZXmtR
All parallelization strategies are implemented from scratch in a modular way, so that you can easily reuse the code in your own projects. We provide Python scripts for each part, so that main functions can be reused across notebooks. We also combine all parallelization strategies in a final example, where we train a large model with 3D parallelism. Check them out on our RTD website!