Training LLMs at Scale
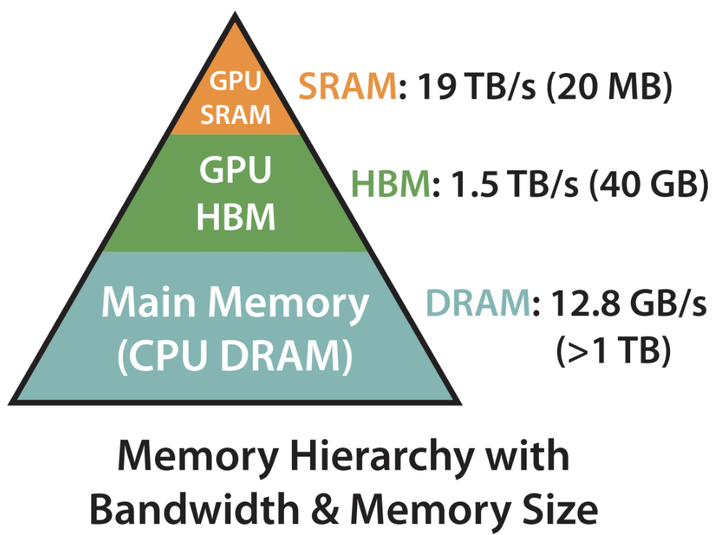 The Memory Hierarchy plays a crucial role in optimizing the training.
The Memory Hierarchy plays a crucial role in optimizing the training.Abstract
In this talk, I provided an introduction to training LLMs at scale. We focused on practical and technical aspects, such as memory and compute management, compilation, and parallelization strategies. I discussed various distributed training strategies like fully-sharded data parallelism, pipeline parallelism, and tensor parallelism, alongside single-GPU optimizations including mixed precision training and gradient checkpointing. We additionally added a short practical section on how to read profiles of large models. The tutorial was framework-agnostic, so no prior knowledge in JAX or PyTorch is needed.
Date
Jul 1, 2024 15:30 — 17:00
Location
Lab 42, Science Park 900, Amsterdam