Training Models at Scale
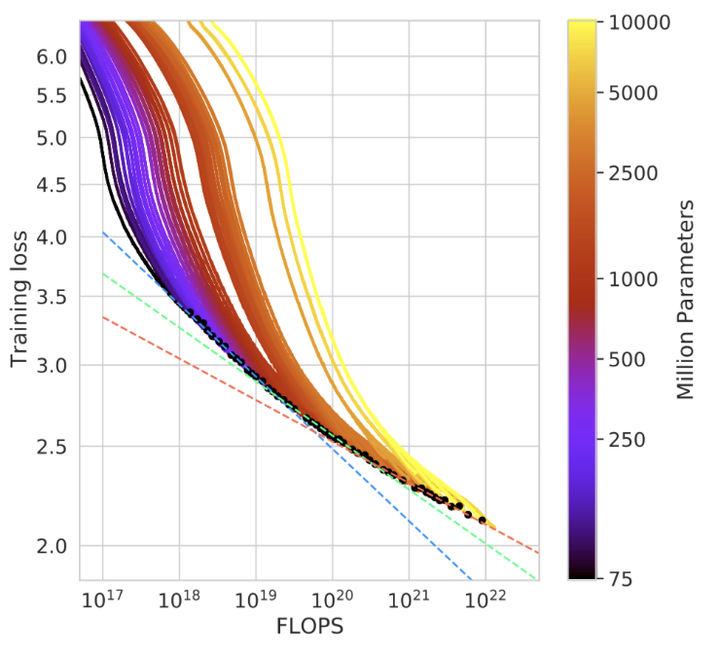 Parallelization techniques enable efficient training of large models like in the chinchilla scaling laws.
Parallelization techniques enable efficient training of large models like in the chinchilla scaling laws.Abstract
I was invited to give a talk on the strategies and concepts behind training large-scale models. I discussed various distributed training strategies like fully-sharded data parallelism, pipeline parallelism, and tensor parallelism, alongside single-GPU optimizations including mixed precision training and gradient checkpointing. The tutorial was framework-agnostic, so no prior knowledge in JAX or PyTorch is needed. By the end, you’ll gain the skills to navigate the complexities of large-scale training.
Date
Mar 11, 2024 17:00 — 19:00
Location
University of Amsterdam